
剂量-反应、浓度-反应和时间-反应关系的分析是毒理学研究的核心组成部分。关于统计分析的一个主要决定是,是只考虑实际测量的浓度,还是假设一个允许外推的基础(参数)模型。最近的研究表明,各种类型的毒理学分析的建模方法的应用。然而,统计方法学研究的最新水平与毒理学文献中发表的分析之间存在差异。在这项工作中,通过广泛的文献综述对这一差距的程度进行了量化,该文献综述考虑了2021年在三个主要毒理学期刊上发表的所有剂量-反应分析。综述的方面包括生物学方面的考虑(检测类型和暴露)、统计设计方面的考虑(测量条件的数量、设计和样本量)和统计分析方面的考虑(显示、分析目标、统计测试或建模方法和警报浓度)。根据本次审查的结果和对统计研究背景下选定的三个问题的批判性评估,从统计角度提出了剂量反应研究的规划、执行和分析的具体指导。
在毒理学研究中,了解化合物的性质及其对人类、动物或细胞的影响是主要目标之一。这通常需要剂量-反应(或浓度-反应、时间-反应等)实验,其中将感兴趣的化合物多次递增剂量施用于单个实验单元组。然后,这些实验的分析可以针对不同剂量与阴性对照的比较,或针对接受相同治疗的几种治疗或几种终点靶点(例如,基因)的比较,或针对计算警戒浓度。一个中心决定是,是否只考虑实际测量的剂量(例如,通过条形图显示,与负对照进行两两比较),还是假设一个基本(参数)模型并拟合到数据中,允许在测量剂量之间进行插值。
在考虑将所测剂量与阴性对照进行两两比较时,常用的方法是Dunnett试验(Dunnett 1955)、Williams试验(Williams 1971)以及进一步的扩展(Tamhane et al. 1996)。就警戒浓度而言,最低观察到的有效浓度(LOEC, Delignette-Muller et al.(2011))或未观察到的不良影响水平(NOAEL, Dorato和Engelhardt(2005))是潜在的途径。
警报浓度一般定义为测量响应值达到或超过某个预先规定的阈值的浓度。这个阈值可以基于绝对值或相对值,也可以包含显著性陈述(Kappenberg et al. 2021)。假设底层模型允许计算警报浓度,该浓度不仅限于测量条件值,而且可能限于两者之间的任何值。虽然ED值(有效剂量,Ritz等人(2019))的计算是活力测定的常见目标,但最近,基于不同模型的警报浓度的计算也被明确推荐用于基因表达测定(Jiang 2013;Kappenberg et al. 2021;M?llenhoff et al. 2022)。
通常,剂量反应实验的设置和分析包括生物学考虑、统计设计和统计分析三个方面。在每个领域,在进行或分析实验之前,需要做出某些决定。关于第一个方面,基于潜在毒理学问题的生物学考虑,化验类型和相应的暴露类型(例如,剂量、浓度、时间)需要加以规定。第二部分涉及实验的(统计)设计。必须在此作出若干决定,这些决定也得到统计数据的支持,例如考虑的剂量数、实际剂量值和各自的样本量。第三步,进行统计分析。这些包括结果的显示、要分析的方面的选择、要使用的测试或建模方法,以及(如果适用的话)要计算的警报浓度。此外,关于统计分析,需要作出关于适当方法的决定。
霍桑(2014),霍桑(2016)给出了在分析剂量反应实验时的统计考虑的概述。这包括有关数据显示的方面、关于如何报告数据分析结果(p值与置信区间)的讨论、针对特定场景的测试概述以及建模考虑事项。Jensen等人(2019)给出了不同基于模型的警报浓度的比较。
然而,统计方法学研究的最新水平与毒理学文献中发表的分析之间存在差异。为了对已发表的分析的潜在改进提供有针对性的建议,有必要量化这种差异在剂量-反应实验的不同方面的程度。因此,本文对三个主要毒理学期刊(《毒理学档案》、《细胞生物学与毒理学》和《毒理学科学》)进行了广泛的文献综述。对2021年以来的所有出版物进行了剂量反应分析筛选,并对确定的分析进行了评估。从生物学考虑、统计设计和统计分析三个方面的相关问题进行评价。如上所述的具体方面代表了相关的问题,这些问题的答案提供了已发表文献中当前技术状况的全面图景。
本文的其余部分结构如下。首先,详细介绍了文献综述和文献综述是如何进行的。所有收集的变量和可能的表达式都在上下文中解释。然后,通过对所有变量进行广泛的单变量分析和一些双变量考虑,提出了文献综述的结果。文献综述的选定结果进行了批判性的讨论,并在统计研究的艺术状态。根据文献综述的结果,从统计的角度为规划、执行和分析剂量-反应实验提供了具体的指导。
在整篇论文中,分析通常被称为“剂量-反应分析”,警报通常被称为“警报浓度”。从统计学的角度来看,不同类型的暴露是等效的。因此,只要没有明确规定,“剂量反应”或“警戒浓度”也分别指所有其他类型的暴露。此外,在这项工作中,“条件”一词被用作一般术语。这个术语包括所有类型的暴露,如浓度、剂量、时间、频率和强度。
在文献综述中,我们选择了三份与毒理学研究具有相当广泛和明确相关性的高级期刊。这三种期刊分别是《毒理学档案》、《细胞生物学与毒理学》和《毒理学科学》。对这三种期刊2021年以来发表的所有文章进行了考虑和筛选,以进行剂量-反应(浓度-反应、时间-反应等)分析。本次筛选只考虑已发表的数据,而不考虑仅在表格中总结或仅在补充数据中呈现的剂量-反应分析。只有当至少有三个条件加上一个阴性对照,或者在没有可用对照的情况下至少有四个条件时,分析才被纳入综述。未考虑基于微分方程的图[例如,基于生理的药代动力学(PBPK)模型]。如果一个图显示了几种剂量反应分析,例如,不同的化合物或一种化合物对不同生物标志物的影响,则每个分析都被单独考虑。
评审是由几个评审人员执行的。为了使结果统一,我们提前准备了一份全面的变量目录,以及它们各自可能的表达式和一些额外的解释和注释。通过举行频繁的会议和讨论,以及广泛的抽样检查和统一工作,解决了审稿人之间可变性的潜在问题。
在本节中,将详细解释收集到的变量及其可能取的值。此外,表1给出了对这些变量、它们可能的值和一些注释的概述。
表1各变量概述在文献综述中,考虑到他们可以采取的可能的价值,并酌情提供进一步的细节和评论
根据学科领域(生物学或统计学)和实验阶段(设计或分析),这些变量可以被分类成不同的组。考虑测定类型和暴露类型的两个变量是剂量-反应实验中的生物学考虑因素,其动机是毒理学研究问题。条件的数量、总体设计和样本量属于实验设计的统计领域,在做决定时也必须考虑分析的总体目标。最后,显示类型、分析目标、分析策略的决策、测试方法、建模方法和警报集中是统计分析的考虑因素。
化验类型
检测类型可以采用“活力”、“酶活性”、“体内”、“增殖”、“诱变性”、“基因表达”、“蛋白质”和“其他”类别之一。一些基于酶的测定(例如LDH测定)用于指示细胞毒性,因此它们适合“活力”和“酶活性”两个类别。在这里,进行了区分,该分析是否只考虑一种酶,在这种情况下,它被分配到“酶活性”类别,或几种酶,在这种情况下,它被分配到“活力”类别。在某些情况下,例如,考虑体内处理后细胞的蛋白质或基因表达测量(例如,将化合物给予大鼠或小鼠,然后在牺牲它们后收获它们的细胞),它们被分配到各自的“蛋白质”或“基因表达”类别,但不属于“体内”类别。“体内”类别仅指直接从动物身上获得的测量结果,例如体重、身高或器官直径。
暴露类型
照射类型分为“浓度或剂量”、“时间”、“频率或强度”和“其他”四类。通常,“剂量”是指给药(如组织或动物)的化合物的总量,而“浓度”描述混合物中应用于(如细胞)的化合物的量。关于“时间”类别,暴露时间和治疗与结果变量测量之间的时间没有差异。在统计建模方面,不同类型的暴露被认为是等效的。
条件数
计算条件的数量,其中控制本身不算数。然而,它被额外记录,是否存在对照。在这里,必须注意的是,对于一些剂量-反应分析,通常会对对照进行一些归一化处理,并且在每种情况下都不会显示对照。在这里进行的审查中,这被视为不存在对照,因为只考虑了图中实际显示的数据。
对于某些数字,例如,在对数轴上的显示,不能或不能准确地检索条件的确切数量。如果可以确定条件数量的合理范围,最多跨越三个数字(例如,“6到8”),则选择最小的相应值(即本例中的6)进行分析。
设计
对于设计,考虑了几个方面。首先,检查各自论文的作者是否对实验设计的选择有任何具体的说明。在第二步中,只要有可能,就从数据中检索实际测量的条件值。毒理学中的典型设计是加法(“等距”)设计和乘法(“对数等距”)设计,其中从某个初始条件值开始,通过添加固定值或与固定值相乘获得剩余条件值。
为了根据等距或对数等距评估检索值,计算条件值(不包括对照)的连续差异和比率。然后对这些连续的差异和比率进行算术复杂度评估,即在这些连续的差异中出现的不同值的数量。因此,连续差异的算术复杂度为1对应于等距设计;连续比率的算术复杂度为1对应于对数等距设计。
仅由三个条件值(和一个负控制)组成的剂量-反应分析总是导致差值和比率的算术复杂度最多为2。因此,具有三个条件值的分析不遵循完全等距或完全对数等距设计(即,不具有1的算术复杂性),分别计算在“非结构化3条件”类别中。所有导致连续差异的算术复杂度为2且连续比率的值高于2的分析都被假设为“几乎等距”,所有这种关系相反的分析都被假设为“几乎对数等距”。
其余的剂量-反应分析被认为遵循不同的或更复杂的设计,并进行了更详细的分析。
样本大小
分别收集对照和非对照条件下的样本量,即每个条件下的重复数。特别是,对于非控制条件,样本量可以在不同的条件下变化,或者在几个实验中表示为范围。在范围不超过4个数字的情况下(例如,“3到6”重复),对于分析,该值被设置为各自的最小值(即本例中的3)。一些跨越4个以上数字但在1到10范围内的范围被汇总到一个单独的类别中,所有其他不符合上述汇总标准的范围也是如此。
显示类型
对于显示类型,考虑了五个不同的类别。第一类是柱状图,其中没有区分纯粹的柱状图和额外提供标准误差或标准偏差信息的柱状图。下一个类别被称为“曲线插值”。这里考虑了线性和非线性插值,即剂量平均响应值的连接。“分散”类别描述的是只显示数据点的情况。在“箱形图”类别中,既有单独的箱形图,也有叠加的单个数据点的箱形图。最后一类被称为“曲线建模”,其中假设并拟合数据的基本参数或非参数模型。
除了这五个类别之外,还评估图中是否包含了一些显著性陈述。在这里,它被区分为恒星和所谓的“(紧凑)字母显示”(CLD) (Piepho 2004)。星号表示特定条件值的响应值与对照值或另一个明确规定的条件值的响应值之间的显著差异。CLD将字母分配给治疗组的方式是,如果两个或多个组共享相同的字母,则它们之间不会发现显着差异。因此,CLD要求对所考虑剂量之间的所有两两比较进行显著性声明,而通常为与(阴性)对照的个体比较提供星号。
分析目标
下一个变量是分析目标,从图和相应的标题中确定。一个剂量-反应分析可以确定几个分析目标。可能的目标包括“比较-对照”,即与最低测试条件值(通常是对照组)进行比较,“比较-治疗”,即不同剂量水平/治疗之间的比较,或用相同化合物处理的不同生物标志物之间的比较,以及“比较-杜克”,即剂量之间的所有两两比较。这些比较都需要某种统计检验。此外,可能的分析目标是“alertConc”,即警报浓度的显式计算(另见关于警报浓度的变量),以及“整个曲线”类别,指的是对剂量-反应分析形状的一般观察。这一类的作业不需要实际的剂量反应模型。
测试方法
为了评价测试方法,收集了关于全局测试程序(例如,方差分析)和关于局部测试程序(例如,与阴性对照的两两比较)的信息。测试方法在相应的论文中被确定,后来被分类为“ANOVA / Kruskal-Wallis / Friedman (only)”(即只进行全局测试)、“t检验/多重比较/ Bonferroni”、“t检验或ANOVA”、“Dunn / Dunnett / Steel / Sidak”、“Holm / Holm-Sidak”、“最不显著差异”、“Mann Whitney U / Wilcoxon”、“Tukey / Tukey- kramer”和“Duncan / Newman-Keuls”组。对于局部测试程序,还要评估在局部测试之前是否进行了全局测试,即是否以两步的方式执行了整个测试程序。
ANOVA指的是方差分析,这是一种检验不同群体响应值均值之间整体差异的统计方法,其中响应假设遵循正态分布(例如,Chambers和Tibshirani 1992)。Kruskal - Wallis检验是针对相同分析目标的非参数、基于秩的替代方法(Kruskal and Wallis 1952), Friedman检验是另一种非参数替代方法,假设配对样本(Friedman 1937)。
学生t检验用于比较两组的均值,同时假设响应为正态分布。Bonferroni方法是一种非常简单的常用方法,用于调整多个测试的p值,以避免I型误差的膨胀并控制家庭错误率(FWER) (Bonferroni 1936)。
在这种情况下,Dunnett程序用于针对(负)控制的多重比较,通过考虑比较之间的相关性,从而在仍然控制FWER的情况下增加整个测试程序的功率(Dunnett 1955)。这是一个参数化过程。Dunn过程也是参数化的,也有类似的目标,但它并不局限于对负控制的测试,而是测试所有可能条件对的任何预定义子集之间的差异(Dunn 1961)。Steel的测试是一种非参数程序,用于同时比较不同条件与负控制(Steel 1959)。?idák(或Dunn -?idák)检验程序是使用修改的显著性水平(?idák 1967)来控制独立检验的FWER的方法。
Holm(降下)程序是Bonferroni程序的一个更强大的替代方案,同样可以控制FWER,但通常通过追求顺序策略导致更少的II型错误(Holm 1979)。Holm -?idák方法是对Holm方法的修改,也是由Holm(1979)提出的,其中以不同的方式计算各自的临界值,也追求在控制FWER的同时增加程序功率的目标。
最小显著差异法的工作原理是,根据正态分布假设,计算特定情况下均值比较具有显著性的最小差异。所有实际观察到的差异大于最初确定的最小值,然后对应于各自的零假设的拒绝(Fisher 1935)。
Mann - Whitney U检验和Wilcoxon检验是两个等效的检验,用于比较基于秩的两个组的均值,即采用非参数程序(Mann and Whitney 1947;Wilcoxon 1945)。
Tukey检验是一种同时确定所有两两比较的显著性的方法。与简单的t检验类似,将均值的标准化差异与某些分位数进行比较,但分位数源于学生化的范围分布,因此该程序控制了FWER (Tukey 1949)。Tukey - Kramer程序是对Tukey程序的修改,也允许在组中不平衡的样本量(Kramer 1956, 1957)。
纽曼-柯尔斯方法是一种类似于杜基方法的多重比较方法。然而,它的目的是通过选择不同的临界值来获得更高的功率,这可能导致不能保持指定的水平(Newman 1939;Keuls 1952)。Duncan的新多射程测试是对Newman-Keuls方法的进一步修改,目标是更高的功率(Duncan 1955)。
建模方法
变量建模方法捕获基于插值的建模和曲线的参数或非参数建模。“线性插值”类别描述了通过分段线性函数将不同剂量的平均响应值连接起来(《数学百科全书》,a)。“非线性插值”也指剂量平均响应值的连接,但这里不是通过线性函数,而是通过一些非线性函数,例如样条(《数学百科全书》,b)。
在参数模型方面,第一类是“Log-logistic/Hill/(sig)Emax”模型。这三个名称都是指同一系列模型的等效参数化。该曲线具有单调的s型形状,根据参数数量的选择,可以灵活地估计渐近线、拐点和斜率的值(Ritz et al. 2019;丽兹2010;方和周2023)。“非线性曲线”类别是指所有没有给出确切模型名称的建模曲线。与对数-逻辑模型相比,对于“指数模型”,曲线在高剂量时不会达到饱和,但它总是以指数方式增加(Bretz et al. 2005)。“线性模型”是指经典的线性回归方法,“模型选择”是指考虑多个模型,并根据某种标准选择一个模型。
在多重比较程序中,剂量值被视为定性(有时是顺序)观测值,与此相反,在建模方法中,条件值总是在定量尺度上考虑。建模允许在实际测量条件值之间进行插值和外推。
一个乐特·浓度拉
对于采用某种剂量-反应模型进行的分析,考虑的警戒浓度分为四类:第一类,“ed值”,考虑有效剂量/浓度。有效剂量被定义为在反应变量中可以观察到预先规定的(相对)效应的剂量,例如,ED10是指可以看到10%的总效应的剂量(Ritz等人,2019;Sebaugh, 2011)。这一类别还包括抑制浓度,其定义类似,但指的是化合物对生物过程的抑制作用(Sebaugh 2011)。基准剂量(BMD)方法给出了对“起点”的估计,即观察到与背景风险不同的反应的最低剂量(Jensen et al. 2019)。“NOAEL”描述了未观察到的不良影响水平,有时也被称为“NOEC”(未观察到的影响浓度),这是与对照相比未见显著或相关影响的最高浓度(Dorato和Engelhardt 2005;Delignette-Muller et al. 2011)。“ALEC”(绝对最低有效浓度)是一种基于模型的警报,其计算方法是建模曲线与预先指定的效果水平相交的浓度(Jiang 2013;Kappenberg et al. 2021)。
软件
评估使用哪种统计软件进行数据分析。这只有在作者明确声明的情况下才有可能,并且纯粹是每篇论文进行评估,也就是说,每篇论文只考虑一个软件(或几个软件的组合)。
barplot通常用于显示文献综述的结果。对于若干变量,给出了两种结果说明,一种是单独考虑每种剂量-反应分析,另一种是按每篇论文分析结果。这种每篇论文的方法意味着,对于一个变量,例如“暴露类型”,每个可能的值,在这个例子中,浓度/剂量、时间、频率/强度和其他,每篇论文只计算一次。因此,如果在一篇论文中考虑三条以浓度为暴露量的曲线和十条以时间为暴露量的曲线,那么Conc/Dose和time只对该论文计算一次。在每个分析被单独考虑的方法中,3条和10条曲线分别计算3次和10次。每篇论文的方法有助于避免结果中的结构性偏差,例如,当一篇论文考虑对同一类型的条件进行异常大量的分析时,这将导致对特定类型的观察结果的非常高的增加,但这并不一定反映通常在出版物中所做的事情。然而,本文并没有对所有变量进行分析,因为其中许多变量(如分析目标,使用的统计方法)并不是完全由实验者做出的决定,而是基于不同实验的目标和一般情况。
摘要
介绍
文献综述
文献综述结果
统计设计和分析指南
讨论与结论
数据可用性
笔记
参考文献
作者信息
道德声明
搜索
导航
#####
在本节中,将介绍文献综述的结果。首先,介绍了每个变量的单变量分析,然后是一些选定的双变量关系。最后,对分析的主要结果进行了批判性评价和讨论。
在统计编程软件R 4.2.2版本(R Core Team 2022)中对文献综述进行分析。对于结果的图形显示,使用了软件包ggplot2 (Wickham 2016),以及附加软件包ggmosaic (Jeppson et al. 2021)和gridExtra (Auguie 2017)。
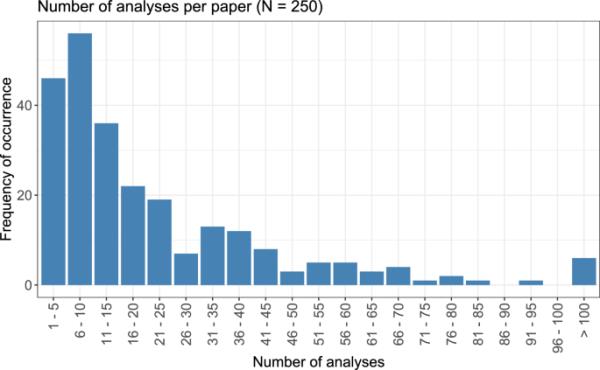
在这三种期刊中,2021年共发表了1644篇论文。在这1644篇论文中,250篇至少包含一项符合选择标准的剂量-反应分析。本综述共考虑了5670项剂量反应分析。每篇论文的剂量-反应分析数量汇总在图1中。虽然大多数论文进行了1-15次剂量反应分析,分析图在6-10次分析时达到峰值,但也有一些论文进行了更多的分析:30 - 45次分析仍然经常被观察到,而50 - 70次分析的数量略少。有些论文甚至包含100多个分析,这些分析在显示的图表中被总结为一个类别。每篇论文考虑的分析的平均值(算术平均值)为22.7,中位数为14,四分位数为6和31。
图1
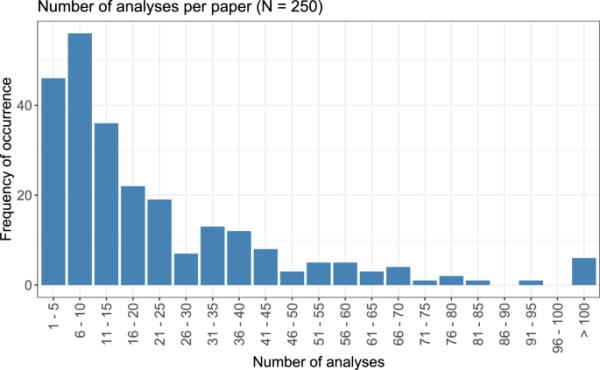
每篇论文所考虑的剂量-反应分析的数目,分别以5个数字为一组。所有高于100的数字都汇总到同一类别
首先,评估化验的类型。图2显示了每种类型化验的发生频率,包括每个分析级别(左)和每个论文级别(右),每个化验在每篇论文中只计数一次。这种每篇论文的方法产生了403个观察结果。这两种分布是相似的:不考虑那些被归类为“其他”的分析,“体内”分析是最常见的,其次是活力分析。“基因表达”和“蛋白质”检测同样频繁,频率仍然相对较高,其次是“酶活性”检测。最后,“增殖”和“诱变”试验是频率最低的。
图2
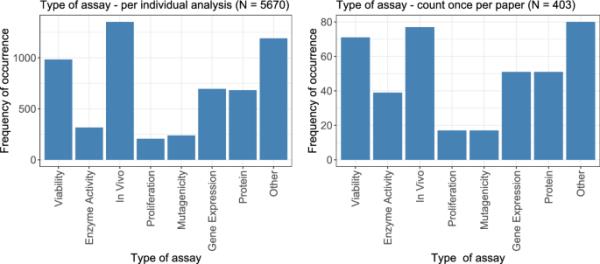
计算了剂量-反应分析中考虑的试验类型。在左边,显示的是每个单独的分析;在右边,每张纸只计算一次化验结果
图3显示了每种暴露类型的发生次数,包括个人水平(左)和每篇论文的总结(右)。在每篇论文的水平上,提出了278条意见。总共考虑了250篇论文,这意味着,在绝大多数论文中,根据这四个类别,只考虑了一种类型的曝光。剂量-反应或浓度-反应分析是最常见的,其次是时间-反应分析。频率、强度和其他暴露很少发生。
图3
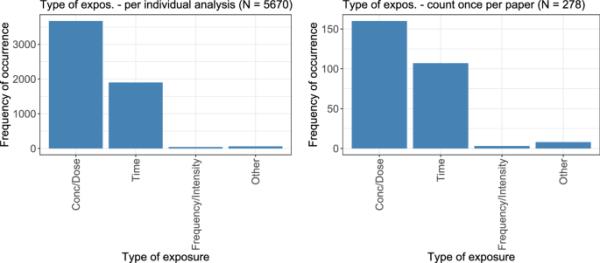
分析中考虑的暴露类型被计算在内。在左边,显示的是每个单独的分析;在右边,每篇论文只计算一次曝光
图4显示了每次分析的条件数,不包括控制。条形图的蓝色部分表示除了规定的条件数量之外还显示了对照的分析,红色部分表示没有显示对照的分析。由于文献综述的纳入标准,该图中没有显示少于三个条件和附加对照或少于四个条件而无对照的分析。
图4
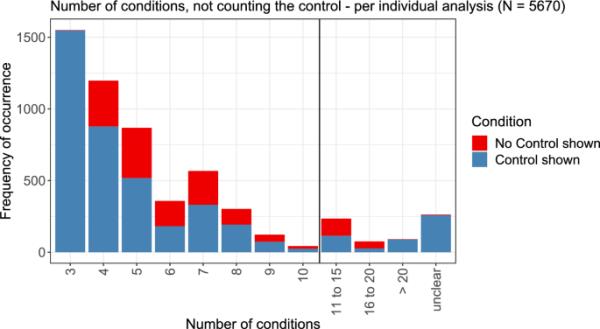
每个剂量-反应分析考虑的条件数,不包括对照。另外显示控制项的那些分析以蓝色显示,其他分析以红色显示。大于10的数字被归纳为三类(在线彩色图)
测量和显示控件比缺乏控件更常见。然而,在1431项考虑的分析中没有显示出对照。三种情况是最常见的情况,其次是四和五种情况。仅在少数情况下观察到较高的数字,但有时也会观察到超过10甚至20个条件。对于某些分析,例如,由于难以读取对数轴或由于同一图中显示的重叠剂量-反应分析,无法检索到数字。
除阴性对照外,三剂量是一种非常典型的设计,包括“低”、“中”和“高”剂量(Hothorn 2016)。这也是本综述中纳入的各自剂量-反应分析的最小条件数。每当采用一种建模方法对剂量-反应数据进行分析时,由于可获得的信息更多,更多的条件通常会导致更好的模型拟合,但至少需要与拟合模型中的参数一样多的条件(包括控制),以确保可识别性。
对所使用的设计进行分析的第一步是找出论文的作者是否明确地提到了所选设计的一些统计考虑。然而,在任何一篇论文中都没有发现这样的信息。因此,作为第二步,在可能的情况下,检索实际条件值,并使用所产生的连续差异和比率的算术复杂度(如上所述)来获取有关底层设计的信息。
在所有5670个分析中,可以检索到4747个分析的条件值。对于36项分析,由于相应的一系列条件值为零(无明显设计,出现3次)和(等距设计,出现33次),因此没有计算连续比率。图5显示了不同设计的结果,这是通过对算术复杂性的分析得出的。
图5
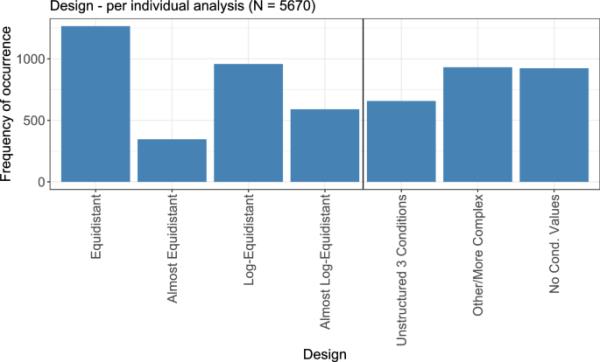
分析了实际工况值的连续差值和比值的算术复杂度所导致的工况值的不同设计
在所有类别中,等距设计(即,附加条件值)最常发生,其次是对数等距设计(即,乘法)。当考虑几乎等距和几乎对数等距设计时,经常观察到两种类型的加法和乘法。
“其他/更复杂”类别中的一类设计是原则上是乘法(对数等距)的设计,但在两者之间有一个附加条件值,不适合对数等距轮廓。一个这样的例子是条件值0.1、1、5、10,中间有三个对数等距值和一个附加条件值。一般来说,“其他/更复杂”类别中的许多分析在视觉上似乎接近等距或对数等距设计,但具有多个加法或乘法因素。
负控制的作用,特别是在建模方法中,是估计响应值的左侧渐近线。类似地,可以在设计中添加一个非常高的值来近似“无穷大”的值,从而帮助估计拟合模型的右侧渐近线。根据从评审论文中检索到的条件值,只有在一篇论文中观察到最高条件的异常极端值,其中以小时为单位测量了时间点0.1、1、2、3、4、5、6、20的时间。然而,作者没有给出具体的理由,并且响应值是通过条形图而不是通过建模曲线显示的,因此在所有考虑的出版物中,从未使用非常高的剂量水平来改进右侧渐近线的估计。
有关适当统计设计的性质和优点的更多详情,请参阅“评估”一节。
对于样本量,对照(如果有)和非对照条件是分开考虑的。图6显示了对照(左)和非对照条件(右)的每个浓度的复制数。如果适用,范围被总结为“分析策略”一节中所解释的。在这两个图中,可以看到每个条件下三个重复的共同数量的最大峰值。6个,5个,4个依次重复。只有极少数分析使用少于3次或多于6次重复。对于相当数量的分析,在各自的出版物中找不到关于样本量的确切信息。
图6
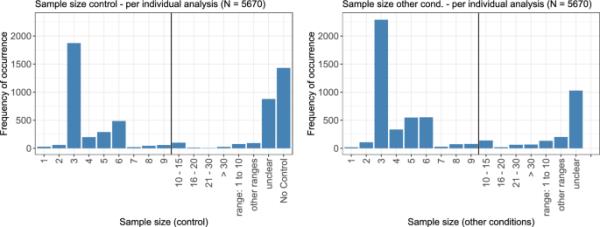
对照(左)和其他条件(右)的每个条件的样本量。较小的范围(例如,2 - 3)被总结为各自较小的值(在本例中为2),其他范围根据值被分配到“范围:1到10”或“其他范围”类别
由于伦理或成本相关的原因,样本量非常小,这是毒理学数据的主要挑战之一(Hothorn 2016)。一般情况下,建议阴性对照的样本量应比其他条件下的样本量高一个因子。这个因子的一个可能的选择是条件数量的平方根。在尽可能减少样本量的同时,将统计检验的效力保持在一个合理的水平,这是长期以来研究中的一个相关课题(sch
茨和富克斯1982),并且往往与实验统计设计的优化密切相关。研究还朝着将历史对照数据纳入新实验的方向进行,以增加阴性对照的样本量(Kluxen et al. 2021;Hayashi et al. 2011)。
当直接比较文献综述中的样本量时,5670个分析中有3259个分析的对照和其他条件的样本量相同或至少在相同的范围内。对于804项分析,没有给出对照或其他条件的信息,对于1431项分析,没有显示对照。只有在66项分析中,对照组的样本量大于其他条件,而在18项分析中,情况正好相反。对于其余的分析,由于对照组或其他条件的值缺失,无法进行比较。Wang and Yang(2014)通过常用的四参数logistic模型进行建模,证明了局部d -最优设计,即使所有四个参数同时置信区域最小化的设计,由四个不同的支撑点组成。Li和Majumdar(2008)推导出这些支撑点中的一个对应于条件值0。在所有四个支撑点上的样本量应该相等,这样所有样本的25%应该分配给对照组(Silvey 1980)。虽然只有少数被审查的论文实际上符合剂量-反应关系的逻辑-逻辑模型,但总的来说,控制中的样本量似乎相当低。
这里没有直接解决的一个挑战是处理技术复制和生物复制的不同方法。有时,第一个处理步骤是计算每剂量所有技术重复的平均值,然后继续,仅利用生物重复来估计每剂量的变异性。然而,这会导致信息的丢失,因此应该避免(Ritz et al. 2019)。另一个挑战在这里没有讨论,但仍然很重要,那就是考虑在组合数据时可能出现的批处理效果。这些差异可能是生物学性质的,例如供体间的原代人类细胞差异,但也可能是技术原因的,例如使用不同批次的测试物质。在实验方面应该知道对数据变异性可能产生的影响,以避免或尽量减少这些影响,在统计方面也应该知道,以便能够在统计分析中考虑到这些影响。
对于各自剂量反应分析的显示,既评估了显示的总体类型,也评估了显示的显著性(如果适用)。总的来说,在所有5670次分析中,有3076次给出了关于重要性的信息,在绝大多数情况下使用了恒星。图7总结了显示的类型,一次是针对单个分析,并附带关于显著性声明的附加信息(左),一次是针对每篇论文的计数,结果是333个观察值(右)。
图7
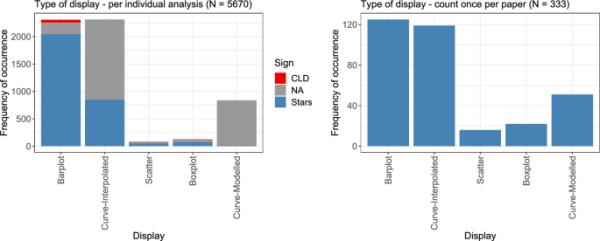
每种类型的显示用于展示剂量-反应分析的次数,无论是在每次分析水平上(左),还是在每篇论文只考虑一次显示时(右)。对于单独的显示,还可以通过星号(蓝色)或CLD(红色)(在线彩色图)来指示图中是否有意义的陈述。
条形图和插值曲线,即大多数线性连接的数据点(参见“建模方法”章节,了解更多关于插值方法的详细信息),显然主导了所选择的显示。barplot几乎总是与一些意义声明结合在一起,几乎完全利用星星,但也很少使用紧凑字母显示(CLD)。一般来说,平均响应值用条形图表示,通常用误差条表示标准偏差或标准误差。
箱形图显示了中位数,两个四分位数,并且根据胡须的具体选择,显示了数据的范围和极值(“离群值”)。尽管箱形图通常比条形图传达更多的信息,但箱形图很少被使用,尽管一些毒理学论文明确建议使用箱形图(Elmore and pedada 2009;Pallmann and Hothorn 2016)。条形图和箱形图都有一个共同的问题,即变量在x轴上的实际值之间的相对差异没有显示出来,因此不能直观地评估总体剂量-反应关系。对于非常小的样本量,箱线图很难解释。然而,箱线图仍然比条形图包含更多的信息,条形图也隐含地假设了正态分布的数据(Hothorn 2016;Pallmann and Hothorn 2016)。
对于建模曲线(即底层模型,主要是参数模型),基本上从未提供显著性信息。显著性通常仅指实际测量的剂量,而参数化建模还允许在剂量之间进行插值。
当每篇论文只计算一次显示时(图7,右图),箱形图的比例更大,但通常,结果与单独分析非常相似。
在这个回顾中,可以为一个分析分配多个分析目标,这样对于5670个分析,总共评估了5917个分析目标。不同目标的频率分布如图8所示。所有涉及某种“比较”的目标都表明在分析中进行了一些统计测试。到目前为止,最常观察到的分析目标是与最低考虑条件进行比较,这通常是控制。接下来是对剂量-反应关系的整体考虑,没有任何明确测试的比较,例如,通过描述剖面的一般增加或减少的形状。比较不同剂量-反应关系是第三个最常见的目标,其次是计算警戒浓度。在所有考虑剂量之间的两两比较很少是剂量-反应分析的目标。有关使用的测试和建模方法以及计算的警报浓度的详细信息,将在随后的章节中给出。
图8
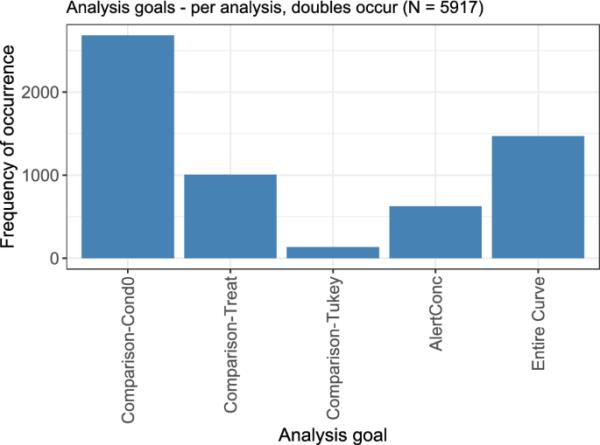
不同分析目标的出现频率。所有涉及“比较”的目标都表示一些统计测试
在论文中使用的测试方法的概述在图9中给出。对于显示的3623个分析中的2217个,执行两步程序,初始全局测试和随后的事后程序。这在条形图中用紫色表示。对于346项分析,只进行了一次整体测试,不允许对个别剂量进行说明。
图9
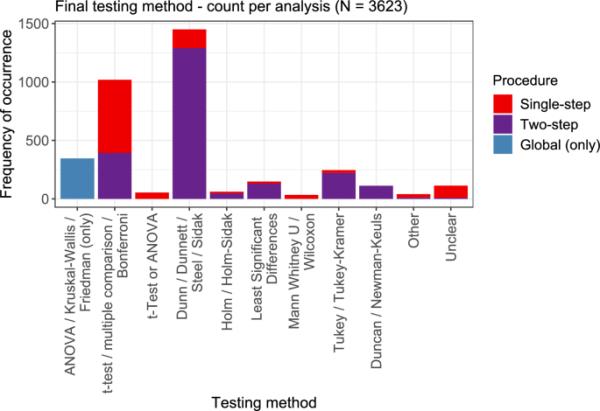
不同测试方法的概述。颜色表示过程的类型,即,如果只执行了一个全局测试,或者只执行了多个比较(单步),或者在一些全局过程(两步)之后作为一个事后测试执行了多个比较。
Dunn/Dunnett/Stell/Sidak分类是最常见的,也是在大多数情况下作为两步程序的一部分。这些程序的主要目的是同时比较每个条件的响应值与负控制。其次是类别t检验/多重比较/Bonferroni,这是一个相对宽泛的类别,因为多重比较方法没有进一步规定。在这个类别中,选择两步方法的频率明显较低。所有其他类别发生的频率要低得多。其中,Tukey/Tukey - kramer方法(即考虑所有两两比较)是最常被选择的方法,其次是最小显著差异方法和Duncan/ Newman-Keuls检验。剩下的方法很少被选择。
Duncan和Newman-Keuls方法出现的次数仍然相对较多,这有点令人惊讶,因为对于这些测试,众所周知,功率的增加是以不保持显著性水平为代价的。在非常流行的GraphPad Prism软件(参见“软件”部分)中,明确不鼓励使用Newman-Keuls测试,脚注1和Duncan测试甚至没有实施,因为它的性能很差。脚注2
虽然两步法显然在已发表的剂量-反应分析中非常流行,但基于统计考虑,通常不鼓励使用它们。这在“评估”一节中有更详细的讨论。
与上面讨论的测试方法相反,建模方法允许将剂量-反应关系插入到任意剂量值。图10显示了每种建模方法的使用次数。在这里,基于插值的方法和具有底层模型函数的方法之间进行了视觉区分。线性插值是目前最常用的方法;另见图7。在非插值模型方法中,逻辑-逻辑模型(也称为Hill或Emax模型)家族是最受欢迎的一种。对于相当数量的分析,具体的模型函数无法从论文中检索到。其他模型,或者考虑到几个模型的模型选择方法,只经常被忽略。
图10
每种建模方法使用的次数,在每个分析级别上显示。该图被一条线划分为插值方法(左)和具有底层模型函数的方法(右)。
关于使用模型拟合分析剂量-反应数据的优点和挑战的更详细讨论,见“评价”一节。
警戒浓度的计算基于描述剂量-反应关系的曲线。图11显示了不同警报浓度的频率,并对每个分析进行了评估。ED值是迄今为止最常计算的警报浓度,在计算警报浓度的所有626次分析中,其频率超过500次。第二个最被考虑的警戒浓度是BMD,而NOAEL和ALEC的发生率可以忽略不计。
图11
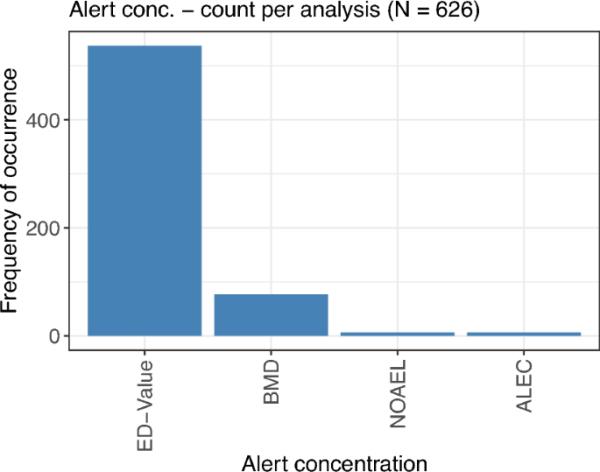
计算每次警戒浓度的次数,所有这些都基于建模或内插的剂量-反应曲线
从技术上讲,无论何时进行与阴性对照的比较(通常由条形图中的星号表示),都要计算最低有效浓度的特殊情况[LOEC, (Kappenberg et al. 2021)],其中仅计算统计显著性,而不考虑生物学相关性。一般来说,LOEC被定义为平均响应值的差异显著超过某个预定义阈值的最低浓度,因此与默认控制中的多次比较对应于阈值为0。然而,在这篇综述中,关于警戒浓度的重点放在那些以明确制定的目标计算的值上,即找到预先指定的警戒浓度,如ED值或BMD,而不是那些只与对照组进行一些比较的分析。
NOAEL的典型用法是有问题的,也经常受到批评。这个警戒浓度的一般定义是,它是与对照相比没有观察到显著差异的最高条件。在统计相关性检验的框架中,不能拒绝零假设并不一定对应于没有效果(Dorato and Engelhardt 2005;Delignette-Muller et al. 2011)。为了正确地假设不存在效应,需要等效检验的统计框架,但是,一般来说,应该优先使用其他措施,如bmd -此外,它利用了整个数据,而NOAEL只考虑了各自的条件水平(Jensen et al. 2019;经合组织2014)
大多数预警浓度的计算是基于拟合(参数)曲线。然而,对于由线性插值显示的少数剂量-反应关系,ED值被计算为插值曲线与预定义百分比值相交的浓度。因此,这些ED值仅依赖于两个相邻条件的响应值,而不利用利用整个数据来拟合模型的可能性。这种ED值应谨慎解释,因为它们受到随机变化的强烈影响。
单变量分析的最后一个变量是使用的软件程序。这纯粹是在每篇论文的基础上考虑的,即250篇观察(论文)。图12显示了用于分析剂量-反应数据和它们各自发生频率的软件。
图12
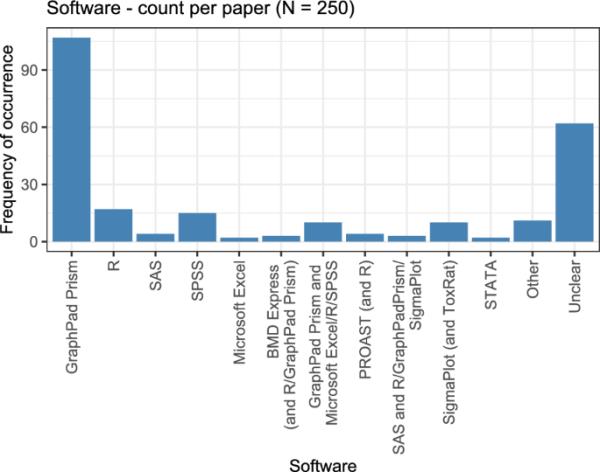
概述用于分析剂量-反应数据和各自发生频率的不同软件
在250篇有剂量反应分析的论文中,有60多篇无法检索到所使用软件的信息。对于其余的论文,GraphPad Prism (www.graphpad.com)在超过一半的情况下使用,有时与其他程序结合使用。统计编程语言R、IBM统计数据分析软件SPSS、科学制图和数据分析软件SigmaPlot的使用比较频繁。其他程序相对较少被提及,有时也在几个软件的组合中被提及。
除了前几节中介绍的单变量分析之外,现在以双变量的方式考虑了变量的有趣组合。结果通过镶嵌图呈现。并不是所有可能的组合都显示出来,但是根据它们所传达的附加信息选择了五对组合。双变量分析仅显示在每个分析水平上(即,不是在每个论文水平上),因为单变量分析的图显示两种方法的结果非常相似。
第一个配对,包括化验类型和显示类型,如图13所示。这里的一个观察结果是,通过“曲线建模”的显示,即具有基础(参数化)模型,用于活力分析的频率远远高于其他分析。在大多数情况下,体内试验和增殖试验的结果通过一些插值显示,并且与其他类型相比,这些类型的试验中通过插值显示的比例也是最高的。对于诱变性、基因表达和蛋白质分析,条形图是最常用的显示方法。总的来说,相对于显示类型的检测类型之间的显着差异可以看出。
图13
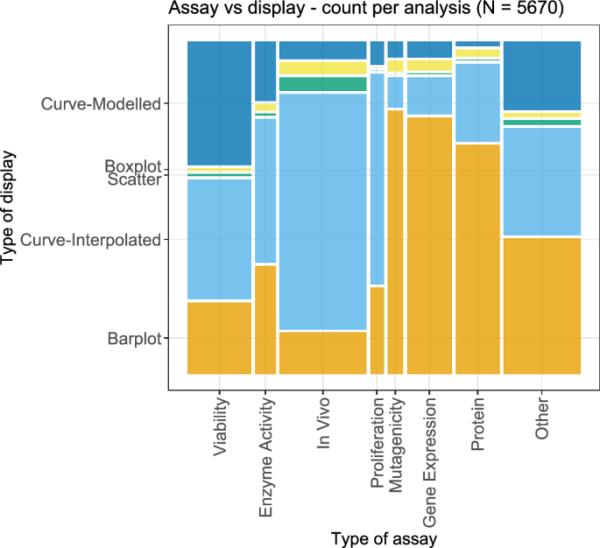
每种考虑的剂量-反应分析的测定类型和显示类型的双变量图
图14显示了化验类型和相应分析目标之间的二元关系。由于对于某些剂量-反应分析,可以确定多个分析目标,因此相关的分析经常相应地重复。在分析类型中,计算警报浓度的分析目标对于活力分析是最常见的,这在原则上符合先前的观察,即建模更经常用于这种类型的分析。在体内,增殖和活力测定通常符合考虑(拟合)曲线整体的总体目标。与最低考虑条件值的比较是一个非常普遍的目标,特别是对于诱变性,基因表达和蛋白质测定。
图14
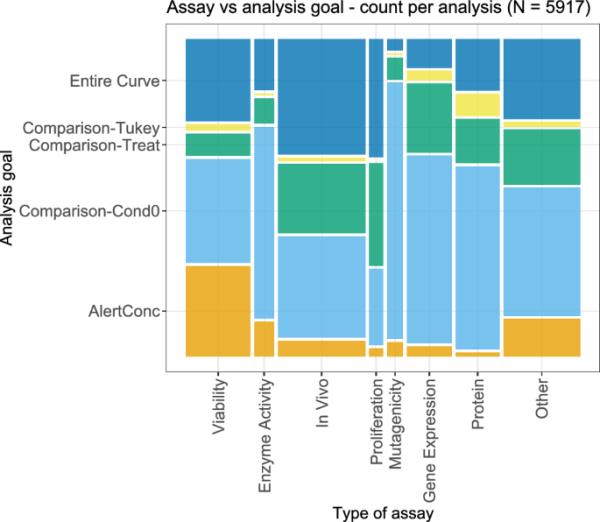
每种剂量-反应分析的试验类型和相应分析目标的双变量图。一些分析有不止一个目标;在这种情况下,它们在这个图中被计算了多次
显示类型和条件数量的二元图如图15所示。与图4中之前的(单变量)图相比,条件的数量被总结在更少的类别中,即数字6-10只构成一个类别,数字11-20也是如此。可以清楚地看到,当结果通过条形图、散点图或箱形图显示时,条件的数量普遍较少,只有三个条件分别是最大的类别。对于通过一些插值或甚至通过曲线建模的显示,条件的数量通常更高。特别是,通过建模曲线的显示,只有三种情况很少发生,最常见的类别是6-10种情况。
图15
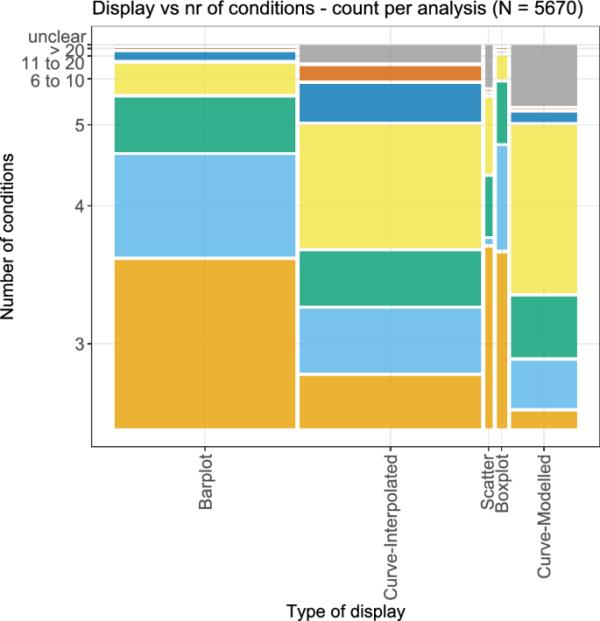
不同类型的显示器对条件数量的双变量图。通过与图4的比较,进一步总结了这些数字
下一个双变量分析,如图16所示,考虑了显示类型和分析目标。与以前一样,由于每个剂量-反应分析可能有多个分析目标,因此相应的显示类型经常被重复。总的来说,研究结果与之前的研究结果一致。对于通过条形图显示的结果,最常见的相应分析目标是与最低条件值进行比较。当通过建模曲线显示结果时,警报浓度的计算是最常见的分析目标。对于其他显示器,警报浓度很少是分析目标,只有在少数情况下,通过基于一些插值的曲线显示。对于建模曲线和插值曲线,通常整个曲线也是感兴趣的分析目标。只有通过柱状图或箱形图显示,考虑所有两两比较是一个相对经常选择的分析目标。
图16
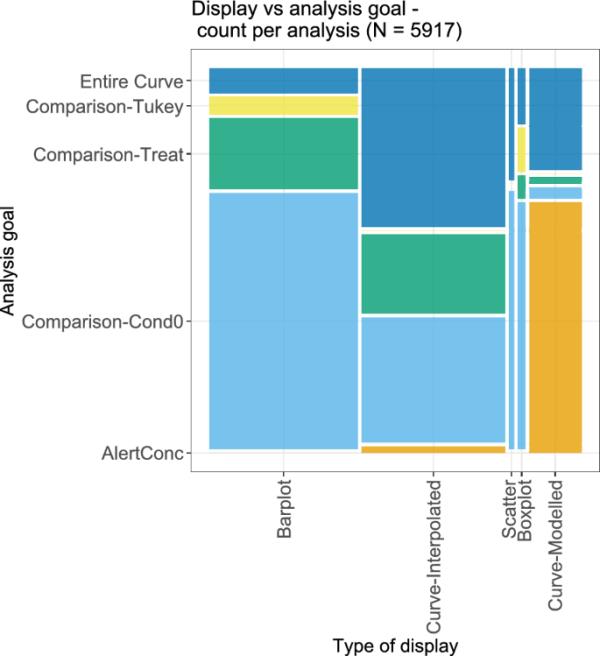
双变量图的不同类型的显示和相应的分析目标。一些分析有不止一个目标;在这种情况下,它们在这张图中出现了好几次
综上所述,可以观察到检测类型和相应统计方法的选择之间的差异,无论是结果的显示还是分析目标。不同类型的显示也与不同类型的分析目标相关联,并且可能由于各自统计方法的不同要求,也对应不同数量的测量条件。
虽然从统计学的角度来看,原则上所有类型的条件值(浓度、剂量、时间等)都是等效的,但它们在实验处理上的差异可能会影响统计考虑的某些方面,例如设计:从实验的角度来看,浓度通常按稀释级数施用,因此在乘法尺度上施用,而时间点的测量可以是任意的。曝光类型与相应设计的关系如图17所示。在这里,可以看到等距或几乎等距设计在时间响应关系中比浓度或剂量响应关系中更常见,在浓度或剂量关系中,对数等距和几乎对数等距设计(即乘标度上的设计)更常见。此外,对于暴露浓度和剂量,无法从各自的图中检索到条件值的情况更为常见。由于缺失的条件值通常是由于在对数轴上显示分析,这也可能在原则上暗示更多的乘法尺度上的设计。对于频率或强度作为曝光的极少数情况,设计要么是等距的,要么是其他/更复杂的类别。
图17
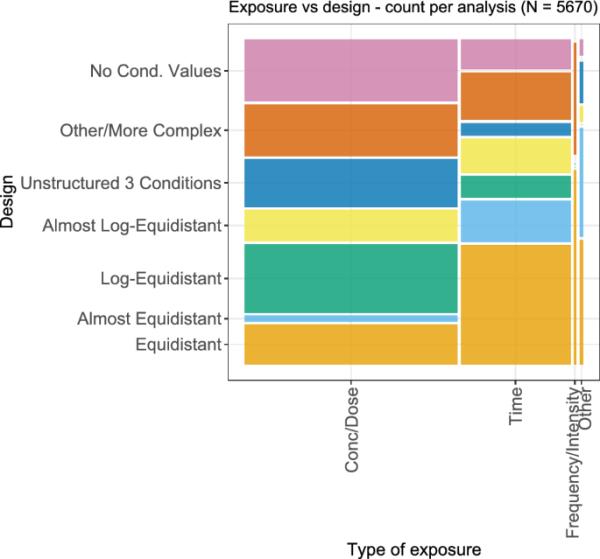
不同类型暴露的双变量图,以及每种考虑的剂量-反应分析的相应选择设计
在本节中,更详细地讨论了剂量-反应关系分析的三个方面,特别是关于统计性质的分析。这三个方面是统计设计的选择,在多重测试环境中使用两步程序,以及建模剂量-反应关系的优势。
第一个方面考虑了基于统计因素决定合适设计的优势。如图17所示,所选择的设计取决于实验中曝光的类型。然而,从统计学的角度来看,暴露类型与实验设计的相关性不如其实际分析目标。
如果计划在不同条件下进行效果比较的多重测试,则将条件固定为感兴趣的值是合适的。此外,在每一种条件下的观察次数应该等于后来使用的多重测试程序的功率最大化,如Wu和Hamada(2011)所示。然而,如果感兴趣的不同条件的数量增加到5个以上,那么多种测试方法的性能,特别是方差分析的性能会下降(Bornkamp et al. 2007)。因此,只要对超过五种不同条件的影响感兴趣,就应该优先采用条件-响应关系的建模(建模的进一步优点将在下面讨论)。
如果计划建模,使用经常出现的等距和对数等距设计(参见图5)可能是不合适的:这些设计可能包含的条件,其观测值不能描述参数模型的相关部分,因此会导致拟合不良。相反,特定于模型的优化设计策略(如d -最优性或复合最优性标准的使用)导致条件的分配,这些条件在方差方面大大优化了最终参数模型的质量(Pinheiro和Bornkamp 2017)。
第二个要点是关于在对阴性对照进行两两测试或同时测试时使用两步程序。如图9所示,首先应用全局测试(例如,方差分析),然后一些所谓的“事后”测试是一种流行的方法。一些用于分析数据的软件也需要这一程序,这是某些研究领域的惯例。然而,这可能会导致结果过于保守,这意味着在全局检验不拒绝全局零假设的情况下,可能存在通过此程序无法识别的群体明智差异,并且只有在拒绝全局零假设后才会考虑两两比较(Hothorn 2016;Midway et al. 2020)。为多重比较选择合适的模型本身是另一个挑战,Midway等人(2020)给出了一些实用的指导。
第三个也是最后一个要详细讨论的方面是,用一些基础(参数)模型来模拟剂量-反应关系,而不是只考虑实际测量的条件值的优点。特别是,对于警报浓度的计算或曲线整体形状的分析,将模型拟合到数据点具有同时使用所有数据点的优点。相比之下,对于插值方法和两两测试,通常只分别使用两个条件。从插值曲线中精确确定警报浓度仅依赖于两个相邻的数据点。
然而,建模的一个主要挑战是选择合适的模型函数。一些应用允许选择基于先前关于典型剂量-反应关系的知识的模型,例如用于活力测定的一般s型形状(由对数逻辑函数族捕获)(Krebs et al. 2020,例如)。对于其他应用程序,模型选择需要以数据驱动的方式执行。一种直接的方法是根据某些信息标准比较几种潜在的模型,或者使用两步程序,如多重比较和建模(MCP-Mod)方法(Bretz et al. 2005)。这种方法也被应用于基因表达数据,并显示出合理的结果(Duda et al. 2022)。
虽然用模拟的剂量-反应曲线分析活力测定,如果适用的话,基于这些曲线计算ED值已经相当普遍(见图13),但最近的研究还考虑了基因表达数据和计算警报浓度“LEC”(最低有效浓度)的可能性,这是一种基于模型的替代流行的“LOEC”(Kappenberg et al. 2021;M?llenhoff et al. 2022)。基于模型的警报的一个优点是它们不依赖于实验的设计;在这种情况下,它们可以取实际考虑的条件值之间的任何值。
下载原文档:https://link.springer.com/content/pdf/10.1007/s00204-023-03561-w.pdf








